
MLOps에 대한 레퍼런스를 찾아 보던 중 개념을 잡기에 좋은 글을 발견하여 번역 및 요약 정리합니다. 원문은 MLOps: Continuous delivery and automation pipelines in machine learing를 참조해주세요. 한글로 번역할 경우에 뜻이 모호해지는 경우에는 영어 그대로 쓰거나 한글과 영문을 병기하였습니다.
본 글은 MLOps는 ML system 개발과 운영을 통합하기 위한 ML engineering의 문화와 관행(practice)에 대해서 이야기 합니다. 업무에 MLOps를 적용한다는 것은 ML system의 전 과정을 자동화하고 모니터링한다는 것을 의미합니다.
ML system에서 좋은 퍼포먼스를 가진 모델을 만드는 것은 중요합니다. 그러나 그러한 일은 ML system 전체의 관점에서 보자면 매우 일부분입니다. 오히려 ML 모델을 잘 굴러가게 해주는 복잡하고 다양한 컴포넌트들을 잘 구성하는 것이 훨씬 중요한 일입니다.
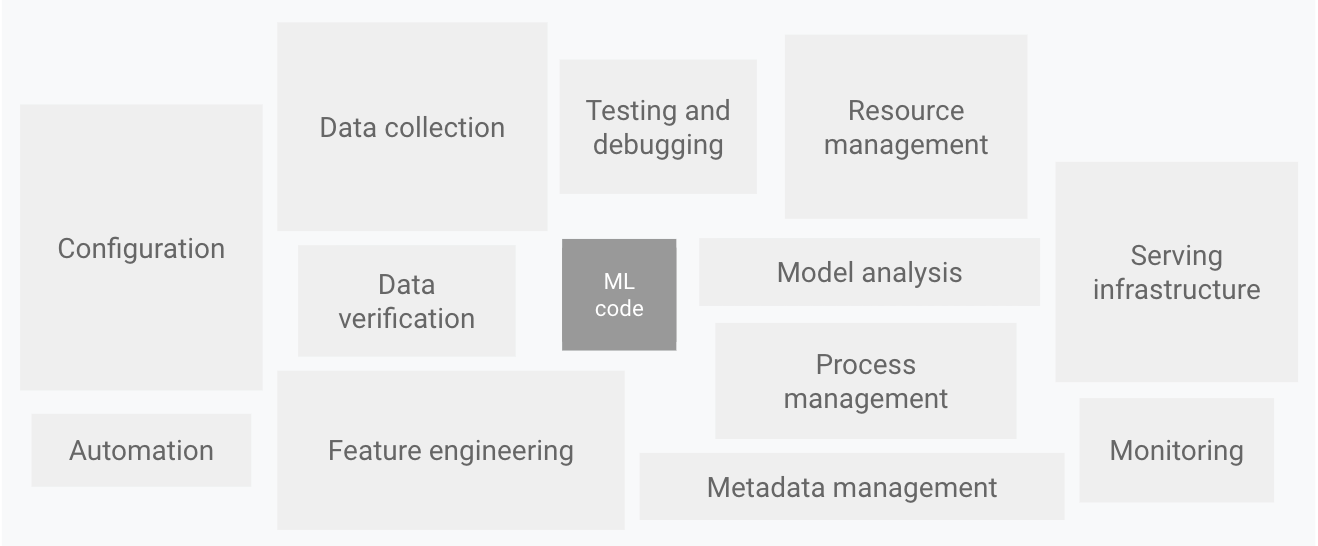 Elements for ML systems, Hidden Technical Debt in Machine Learning Systems
Elements for ML systems, Hidden Technical Debt in Machine Learning Systems
이런 컴포넌트들을 통합하는 시스템을 개발하고 운영하기 위해서는 DevOps의 원칙을 ML system에 적용할 필요가 있습니다 (MLOps). 본 글에서는 다음의 주제들을 다룰 계획입니다.
- DevOps versus MLOps
- Steps for developing ML models
- MLOps maturity levels
DevOps versus MLOps
DevOps란 large-scale의 소프트웨어 시스템을 개발하고 운영하는 가장 인기 있는 practice입니다. DevOps를 떠 받치는 가장 중요한 두 가지 개념이 있습니다.
- Continuous Integration (CI)
- Continuous Deliver (CD)
ML system도 필연적으로 소프트웨어 시스템이기 때문에 DevOps의 원칙을 똑같이 적용할 수 있습니다. 그러나 ML systems은 전통적인 소프트웨어 시스템과 다른 부분이 있습니다.
- Team skills: ML 프로젝트에 참여하는 데이터 사이언티스트들은 보통 숙련된 소프트웨어 엔지니어가 아닙니다. 이들은 보통 EDA, 모델 개발, 실험 업무에 집중하고 있으므로 소프트웨어 개발 프로세스를 잘 이해하지 못하고 있을 가능성이 높습니다.
- Development: ML은 실험의 영역입니다. 데이터 사이언티스트들은 새로운 모델을 실험하고, 피쳐 엔지니어링을 진행하는 등의 실험을 반복적으로 진행합니다. 문제는 이러한 실험을 추적하거나 코드의 재사용성 등의 품질을 관리하기가 어렵다는 것입니다.
- Testing: ML 시스템은 전통적인 소프트웨어 시스템보다 테스트가 필요한 영역이 많습니다. 전통적인 단위 테스트(unit test)와 더불어서 데이터 및 모델 검증 등이 추가로 필요합니다.
- Deployment: ML 시스템의 배포는 생각보다 간단하지 않습니다. ML 시스템은 여러 단계의 자동화된 파이프라인으로 이루어져 있으며, 이러한 파이프라인은 배포의 복잡성을 증대시킵니다.
- Production: ML 모델의 퍼포먼스는 코드의 품질에 따라서도 결정되지만 데이터의 변화에도 큰 영향을 받습니다. 다시 말하면, 모델의 성능이 하락하는 요인이 전통적인 소프트웨어 영역보다 다양하다는 것입니다. 따라서 데이터의 통계량을 추적 및 모니터링 해야하며 기대와 다른 경우에는 알람을 보내거나 roll back 하는 등의 추가적인 작업이 필요합니다.
ML 시스템은 전통적인 소프트웨어 시스템과 같이 소스 코드 형상 관리, 단위 테스트, CI, CD 등의 개념이 필요합니다. 그러나 ML 시스템은 전통 소프트웨어 시스템과 매우 주목할만한 차이점이 존재합니다.
- CI(Continuous Integration): code를 테스트하거나 검증하는데 그치지 않습니다. data value와 data schema, model을 검증하는 것도 고려해야 합니다.
- CD(Continuous Delivery): 하나의 소프트웨어 패키지나 서비스를 배포하는데 그치지 않습니다. ML model을 서빙하는 서비스를 자동으로 배포하는 system(ML training puipeline) 자체를 배포하는 것도 고려해야합니다.
- CT(Continuous Training): 기존 소프트웨어 개발에 없던 새로운 개념입니다. CT는 자동으로 모델을 재학습하고 모델을 서빙하는 프로세스를 의미합니다.
Steps for developing ML models
 Architecture for MLOps using TFX, Kubeflow Pipelines, and Cloud Build
Architecture for MLOps using TFX, Kubeflow Pipelines, and Cloud Build
ML 프로젝트를 작업을 크게 나누어 본다면 다음의 단계들로 이루어져 있습니다. 각 단계는 수동으로 진행되거나 자동화된 방식으로 진행됩니다.
- Data extraction: 모델 학습에 필요한 데이터를 data source에서 선별하고 가져옵니다.
- Data analysis: data의 특성과 schema를 탐색하고 피쳐 엔지니어링을 위한 EDA를 진행합니다.
- Data preparation: 피쳐 엔지니어링을 하거나 데이터를 학습, 검증, 테스트 셋으로 구분합니다. 이 단계의 산출물은 학습에 쓸 수는 format으로 변환된 데이터입니다.
- Model training: 준비된 데이터로 학습을 진행합니다. 또한 이 단계에서 hyperprameter 튜닝을 진행할 수 있습니다. 이 단계의 산출물은 학습된 ML 모델입니다.
- Model evaluation: 학습된 모델에 테스트 셋을 적용하여 모델의 퀄리티를 평가하는 단계입니다. 이 단계의 산출물은 모델의 퀄리티를 평가할 수 있는 metrics(e.g., acc, precision, recall, …)입니다.
- Model validation: 모델이 production 환경에 배포되어도 괜찮은지 검증하는 단계입니다. 특정 기준보다 더 나은 퍼포먼스를 보이는지 검증합니다.
- Model serving: validation 단계를 통과한 모델이 production 환경에 배포되는 단계입니다. (REST API 등)
- Model monitoring: 배포된 모델의 퍼포먼스를 지속적으로 모니터링 하여 모델의 성능 이슈를 지속적으로 점검 하는 단계입니다.
MLOps maturity levels
앞서 ML 시스템이 수행하는 작업을 여러 단계로 나누어 살펴보았습니다. 각 단계는 자동화 수준에 따라 0~2단계로 구분할 수 있습니다. 이를 ML 시스템의 성숙도(maturity)로 정의하겠습니다. 이제부터 ML 시스템의 성숙도별로 특징을 살펴보도록 하겠습니다.
MLOps level 0: Manual process
 Manual ML steps to serve the model as a prediction service
Manual ML steps to serve the model as a prediction service
ML 시스템의 전 단계가 수동으로(manual) 이루어집니다. level 0 단계의 특징은 다음과 같습니다.
- Manual, script-driven, and interactive process: 모든 단계(데이터 분석, 준비, 학습, 검증 등)가 수동으로 이루어집니다.
- Disconnection between ML and operations: 모델링과 서빙이 분리되어 있습니다. 데이터 사이언티스트는 ML 모델을 만들고 그 결과물을 모델 배포를 담당하는 엔지니어링 팀에 넘겨줍니다.
- Infrequent release iterations: 데이터 사이언스팀이 담당하는 모델이 개수가 적어서 모델 배포가 자주 일어나지 않습니다.
- No CI: CI 단계가 없습니다. 코드의 테스트 및 검증은 노트북 파일이나 스크립트를 수동으로 실행하면서 일어납니다.
- No CD: 모델 배포가 자주 일어나지 않기 대문에 CD가 고려되지 않습니다.
- Deployment refers to the prediction service: 배포는 학습된 모델을 서빙하는 것만 고려됩니다. 자동화를 위한 전체 ML 시스템 파이프라인에 대한 배포는 고려되지 않습니다.
- Lack of active performance monitoring: 모델의 예측 결과 등이 추적되거나 로깅되지 않습니다.
MLOps level 1: ML pipeline automation
 ML pipeline automation for CT
ML pipeline automation for CT
level 1의 목적은 ML 파이프라인을 자동화 하여 CT(continuous training)을 성공적으로 수행하는 것입니다. 이는 모델의 CD(continuous delivery)를 가능하게 합니다. level 1은 다음과 같은 특징이 있습니다.
- Rapid experiment: ML 실험 과정이 구조화(orchestrated)되어 있습니다. ML 실험의 각 단계가 자동화 되어 있어 실험을 빠르게 반복할 수 있습니다.
- CT of the model in production: 새로운 데이터로 모델을 학습시키는 과정이 자동화되어 있습니다.
- Experimental-operational symmetry: 개발 또는 실험 환경에서 사용하는 ML pipeline을 운영 환경에서도 동일하게 활용합니다. 이는 MLOps의 중요한 특징 중 하나입니다.
- Modularized code for components and pipelines: ML pipeline을 구축하기 위해 사용되는 components(검증, 학습 등)은 재사용성을 높이기 위해 모듈화(modularized) 되거나 컨테이너화(containerized) 되어야 합니다.
- Continuous delivery of models: ML pipeline은 새로운 데이터로 학습된 모델을 지속적으로 배포(CD) 합니다. 모든 과정이 자동화 되어 있습니다.
- Pipeline deployment: 모델 학습과 관련된 전체 ML pipeline(e.g., kubeflow pipeline, airflow 등)이 배포됩니다.
level 1의 가장 큰 특징은 CT가 도입되었다는 것입니다. CT를 위해서는 다음의 component들이 추가적으로 필요합니다.
Data and Model validation
- Data validation: 이 단계는 모델을 retrain 시켜야할지 아니면 training 파이프라인의 동작을 멈춰야할지 결정하기 위해 필요합니다. 그 의사결정은 다음의 세부 사항들을 보고 결정할 수 있습니다.
- Data schema skews: data schema skew는 downstream 작업에 영향을 미치는 이상치(anomalies)를 말합니다. 만일 ML 파이프라인에 기대했던 스키마에 맞는 데이터가 들어오지 않는다면 ML 파이프라인의 동작을 멈추고 이를 디버깅 해야합니다.
- Data values skews: daga value skew는 유의한 수준의 데이터 통계량의 변화를 듯합니다. 만일 데이터의 패턴이 급격하게 변화되었다면 모델 재학습을 진행해서 변화된 패턴을 capture해야 합니다.
- Model validation: 이 단계는 모델 학습이 성공적으로 이루어진 뒤에 이루어집니다. 학습된 모델은 metric을 평가(evaluate) 받아야 하고, 운영 환경에 배포하기 전에 검증(validate) 하는 단계를 거쳐야 합니다. 이 과정은 offline model validation에 가깝습니다.
- Producing evaluation metric values: 테스트 셋으로 학습된 모델의 metric을 평가합니다.
- Comparing the evaluation metric values: 새로 학습된 모델과 현재 버전의 모델의 metric을 비교하여 배포 여부를 결정합니다.
Feature store
feature store란 학습과 서빙에 사용되는 공통적인 feature들은 모아 놓은 저장소(repository)를 의미합니다. feature stores를 구축하면 다음과 같은 이점을 얻을 수 있습니다.
- 각 모델별에서 공통적으로 사용하는 feature를 관리하므로 비효율성을 방지하고 재사용성을 향상
- 사람에 따라 서로 다르게 feature를 정의하는 혼돈을 방지
- training-serving skew를 방지
- training에 사용했던 feature를 서빙 타임에도 동일하게 사용하여 training과 서빙이 서로 다른 feature를 사용하여 발생할 수 있는 skew를 방지
Metadata management
ML pipeline의 실행과 관련된 정보 (버전, 시작 및 종료 시간, 파라미터 등)을 기록하여 재현성을 높이고 버그 발생 가능성을 낮춥니다.
ML pipeline trigger
다음과 같은 use case에 맞춰서 ML 파이프라인 실행을 자동화 할 수 있습니다.
- On demand
- On a schedule
- On availabiltiy of new trainig data
- On model performance degradation
- On concept drift(significant changes in the data distributions)
MLOps level2: CI/CD pipeline automation
 CI/CD and automated ML pipeline
CI/CD and automated ML pipeline
MLOps level 2에서는 자동화된 학습(CT)가 큰 특징이었습니다. ML은 태생적으로 실험의 영역이므로 새로운 아이디어를 자유롭게 실험하고 ML pipeline의 각 component (e.g. 모델 아키텍처 변경, 피쳐 엔지니어링, 하이퍼파라미터 변경 등)를 빠르게 배포할 수 있어야 합니다. 이를 위해서는 ML 파이프라인에 CI/CD가 셋팅되어야 합니다.
MLOps level 2는 다음의 구성 요소들을 포함하게 됩니다.
- Source code control
- Test and build services
- Deployment services
- Model registry
- Feature store
- Ml metadata store
- ML pipeline orchestrator
Continuous integration (CI)
CI는 새로운 코드가 commit 되었을 때 ML 파이프라인의 구성 요소들을 빌드, 테스트, 패키징하는 과정을 의미합니다. 예를 들어 CI는 다음의 테스트들을 포함할 수 있습니다.
- 피쳐 엔지니어링 로직에 대한 단위 테스트(unit test)
- 모델에 dummy 데이터를 넣어서 학습이 수렴되는지 (오버피팅이 되는지)를 확인
- 모델 학습 과정에서 NaN 값이 발생하지 않는지 확인
- ML 파이프라인의 각 컴포넌트들의 artifacts가 기대되는 것처럼 산출되는지 확인
- ML 파이프라인의 각 컴포넌트들이 서로간에 잘 연결되는지 확인
Continuous delivery (CD)
CI를 통과하면 새로운 ML pipeline의 구성요소들이 target environment(개발 또는 운영 환경)에 자동으로 배포되도록 만들어야 합니다. 이를 CD라고 하며 다음의 작업들이 고려되어야 합니다.
- 학습된 모델을 배포하기 전에 해당 모델의 target infastructure와의 호환성(compatibility)를 검증합니다. 예를 들어 메모리나 CPU 스펙이 해당 모델을 서빙하기에 적합한지 검증합니다.
- 기대하는 input 값과 함께 API를 호출하여 적절한 reponse가 오는지 확인합니다. 이 테스트는 모델을 업데이트하거나 input 값을 변경하였을 때 발생할 수 있는 문제를 발견할 수 있습니다.
- 서빙 API의 퍼포먼스를 테스트합니다. 여기에는 부하 테스트(load testing)를 통한 QPS(queries epr seconds)나 latency에 대한 체크가 포합됩니다.
- development branch에 코드가 commit 되었을 때 test 환경에 배포가 자동적으로 이루어지도록 합니다.
- main branch에 동료의 review를 통해 코드가 merge 되었을 때, pre-production 환경에 semi-automated 배포가 이루어집니다.
- pre-production 환경에서 ML pipeline이 수차례 성공하고 나서 production 환경에 수동으로 배포가 이루어집니다.
Summary
ML 모델을 production 환경에 배포하는 일은 단순히 서빙 API를 배포하는 것에 그치지 않습니다. ML의 실험 정신을 잘 살리기 위해서는 ML 파이프라인의 전 과정이 자동화 되어야 합니다. 이를 위해서는 CI, CD, CT가 고려된 ML 파이프라인을 설계하는 것이 중요합니다. 잘 설계된 ML 파이프라인은 데이터의 변화나 이상치에 긴밀하게 대처할 수 있으며, 적절한 시기에 모델을 다시 학습 시킬 수도 있습니다. 물론 한번에 level 0에서 level 2로 점프할 수는 없습니다. 점진적으로 개선해 나가세요!