
우리는 앞선 글들에서 컴퓨터는 0과 1, 즉 2진수만 이해할 수 있다는 사실을 알았습니다. 그런데 코딩을 해보신 분들은 당연히 아시겠지만 우리는 0과 1로 코딩을 하고 있지 않습니다. 쉽진 않지만 영어로 이루어진, 그래도 인간이 보고 어느 정도 해석을 할 수 있는 언어(파이썬, C, 자바 등)를 이용해서 코딩을 하고 있죠.
컴퓨터는 분명히 0과 1만 이해할 수 있다고 하였는데, 소스 코드를 컴퓨터가 어떤 과정을 통해서 이해하고 실행을 할까요? 제가 주로 사용하는 언어인 파이썬을 통해서 이 과정을 살펴보겠습니다.
배경지식
흔히 파이썬은 인터프리터 언어라고 표현합니다. 인터프리터 언어가 무엇일까요? 파이썬이나 C 혹은 java로 짠 소스코드를 결국엔 0과 1로 이루어진 코드로 바꾸어야 합니다. 0과 1로 이루어진 코드를 기계어(machine code)라고 합니다.
인터프리터 언어는 파이썬 코드 한줄 한줄을 머신 코드로 번역하고 실행합니다. 하지만 다른 언어, 예를 들어 C언어는 소스 코드 전체를 기계어로 변환을 해 놓고, 그 기계어를 cpu가 바로 실행하는 방식을 취합니다. 이러한 언어를 컴파일 언어라고 합니다. 또한 컴파일 언어와 인터프리터 언어를 절충한 하이브리드 언어도 있습니다.
각 방식마다 특징 및 장단점이 존재하는데요. 파이썬의 동작 방식을 이해하기 위한 배경지식으로 컴파일 언어, 인터프리터 언어, 하이브리드 언어의 작동 방식을 살펴보겠습니다.
컴파일 언어
특징
컴파일 언어는 소스 코드를 다음의 과정을 거쳐서 기계어로 변환합니다. 만일 다음과 같이 C언어로 작성된 코드(test.c)가 있다고 가정해 봅시다. 컴파일 과정에 따라 어떻게 변화하는지 살펴 보겠습니다.
1
2
3
4
5
6
7
#include <stdio.h>
int main()
{
printf("hello world!\n");
return 0;
}
precompile:
precompile 단계에서는 본격적인 compile에 앞서 사전 준비를 하는 단계입니다. 예를 들어 C언어에서
#include <stdio.h>와 같은 문법은 소스 코드에서 다른 헤더 파일을 참조하라는 의미인데요. 이러한 파일들은 여전히 C 소스 코드 형태이며stdio.h파일 내용을 소스코드에 포함 시키는 행위가 이루어집니다.test.c소스코드는 아래의 명령어를 통해 전처리를 거친test.i파일로 변환 할 수 있습니다.1
gcc -E test.c -o test.i
test.i파일을 확인해 보면 다음과 같습니다.stdio.h에 있던 모든 소스 코드 파일이test.c파일에 합쳐져 있습니다. 중요한 점은 전처리 과정이 끝나도 여전히 소스 코드 형태, 즉 고급 언어로 이루어져 있다는 것입니다.1 2 3 4 5 6 7 8 9
typedef signed char __int8_t; ... int printf(const char * restrict, ...) __attribute__((__format__ (__printf__, 1, 2))); ... int main() { printf("hello world!\n"); return 0; }
compile:
compile은 소스코드를 기계어로 변환하는 첫 출발점입니다. compile의 결과, 소스 코드는 어셈블리어로 변환됩니다. 어셈블리어란, 고수준 언어와 기계어의 중간에 존재하는 저수준 언어입니다. 어셈블리어는 C와 같은 고수준 언어에 비해 더욱 기계에게 친숙한 언어입니다. 기계어는 cpu가 읽어서 실행할 수 있는 0과 1로 이루어진 명령어의 조합인데요. 이를 사람이 읽고 해석하기가 어렵습니다. 어셈블리어는 기계어를 사람이 좀더 쉽게 읽을 수 있는 기호로 표현한 언어입니다. 어셈블리어의 각 명령문을 instruction이라고 하는데, 기계어와 1:1로 매칭이 되며 CPU 제조사 마다, 사용하는 컴파일러에 따라 instruction이 다릅니다.
아래 명령어로 전처리된 파일을 컴파일 하여 어셈블리어로 작성된 파일을 얻을 수 있습니다.
1
gcc -S test.i -o test.s
test.s파일을 열어 보면 다음과 같이 어셈블리어로 작성되어 있고, 뭔가 명령어(instruction) 형태(pushq,movb,addq등)로 이루어졌음을 알 수 있습니다.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
.section __TEXT,__text,regular,pure_instructions .build_version macos, 10, 15, 4 sdk_version 10, 15, 4 .globl _main ## -- Begin function main .p2align 4, 0x90 _main: ## @main .cfi_startproc ## %bb.0: pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset %rbp, -16 movq %rsp, %rbp .cfi_def_cfa_register %rbp subq $16, %rsp movl $0, -4(%rbp) leaq L_.str(%rip), %rdi movb $0, %al callq _printf xorl %ecx, %ecx movl %eax, -8(%rbp) ## 4-byte Spill movl %ecx, %eax addq $16, %rsp popq %rbp retq .cfi_endproc ## -- End function .section __TEXT,__cstring,cstring_literals L_.str: ## @.str .asciz "hello world!\n" .subsections_via_symbols
assembling:
어셈블리어를 0과 1로 이루어진 기계어로 변환하는 과정입니다. assembling 과정을 거친 아웃풋을 오브젝트 코드(object code)라고 합니다. 이 과정을 거쳐야만 cpu가 실제로 명령을 수행할 수 있게 됩니다. 만일 컴파일할 소스 코드가 하나라면 컴파일 과정은 여기까지만 진행됩니다. 혹시 컴파일할 코드가 여러개라면 linking 과정이 필요합니다. 다음의 명령어로 어셈블리어를 기계어로 변환할 수 있습니다.
1
gcc test.s -o test.o생성된
test.o파일을 확인해 보면 사람이 읽을 수 있는 형태가 아님을 확인할 수 있습니다.1
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^ @^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^ @^@^@^@UH<89>åH<83>ì^PÇEü^@^@^@^@H<8d>=4^@^@^@°^@è^M^@^@^@1É<89>Eø<89>ÈH<83>Ä^P]Ãÿ%p^P^@^@L<8d>^]q^P^@^@ASÿ%a^@^@ ^@<90>h^@^@^@^@éæÿÿÿhello world!
linking:
여러 오브젝트 코드를 합쳐서 실행 가능한 형태의 파일(
.exe,.out등)으로 만드는 과정입니다.
장점
- 컴파일이 완료되었을 경우 해당 파일을 바로 실행하면 되기 때문에 시간상 효율적입니다.
- 그리고 컴파일된 파일은 기계어로 이루어져 있기 때문에 실행 속도가 빠릅니다.
단점
- 소스 코드가 수정된다면 다시 컴파일을 해야 한다는 불편함이 있습니다.
- 플랫폼에 의존적입니다(플랫폼 의존 및 독립의 개념은 부록에 정리해 두었습니다).
인터프리터 언어
특징
인터프리터 언어는 소스 코드를 한번에 컴파일 한 후 처리하지 않습니다. 소스 코드 한줄 한줄을 바로 기계어로 번역한 후 실행시킵니다.
장점
- 소스 코드를 수정해도 수동으로 컴파일을 할 필요가 없기 때문에 개발 속도를 빠르게 가져갈 수 있습니다.
단점
- 한줄 한줄 기계어로 번역하면서 실행하기 때문에, 컴파일 언어에 비해서는 속도가 느립니다.
- 플랫폼 독립적입니다(플랫폼 의존 및 독립의 개념은 부록에 정리해 두었습니다).
하이브리드 언어
특징
컴파일 방식은 플랫폼에 의존적이지만 미리 컴파일한 기계어를 바로 실행하기에 속도가 빠릅니다. 반명 인터프리터 방식은 플랫폼에 독립적이지만, 한줄 한줄 기계어로 번역하여 실행하기 때문에 속도가 느립니다. 하이브리드 언어는 이 두 가지 방식을 적절하게 혼합한 언어입니다.
하이브리드 언어의 큰 특징은 다음과 같습니다.
- 바이트 코드(byte code): 일종의 중간 단계에 있는 코드입니다. 하이브리드 언어의 컴파일러는 소스코드를 바이트 코드로 변환합니다.
- 가상 머신(virtual machine): 프로그래밍 환경을 제공하는 일종의 프로그램입니다. 바이트 코드를 한줄 한줄 번역하여 컴퓨터가 실행할 수 있는 머신 코드로 바꾸는 역할을 합니다.
하이브리드 언어는 플랫폼 독립적이라는 것이 큰 특징인데요. 바로 위에서 언급한 바이트 코드와 가상 머신이라는 두 가지 요소가 있기 때문이 가능합니다.소스 코드를 바로 기계어로 번역하지 않고 바이트 코드라는 중간 단계 구현물을 사용했기 때문입니다.
장점
- 플랫폼 독립적입니다.
단점
- 여전히 컴파일 언어에 비해서 빠르지는 않습니다.
- 컴파일 언어처럼 하드웨어를 직접 제어하는 작업은 어렵습니다.
파이썬 작동 방식
파이썬은 인터프리트 언어로 자주 언급됩니다. 그러나 파이썬은 정확하게는 하이브리드 언어라고 볼 수 있습니다. 다음과 같은 특징이 있기 때문입니다:
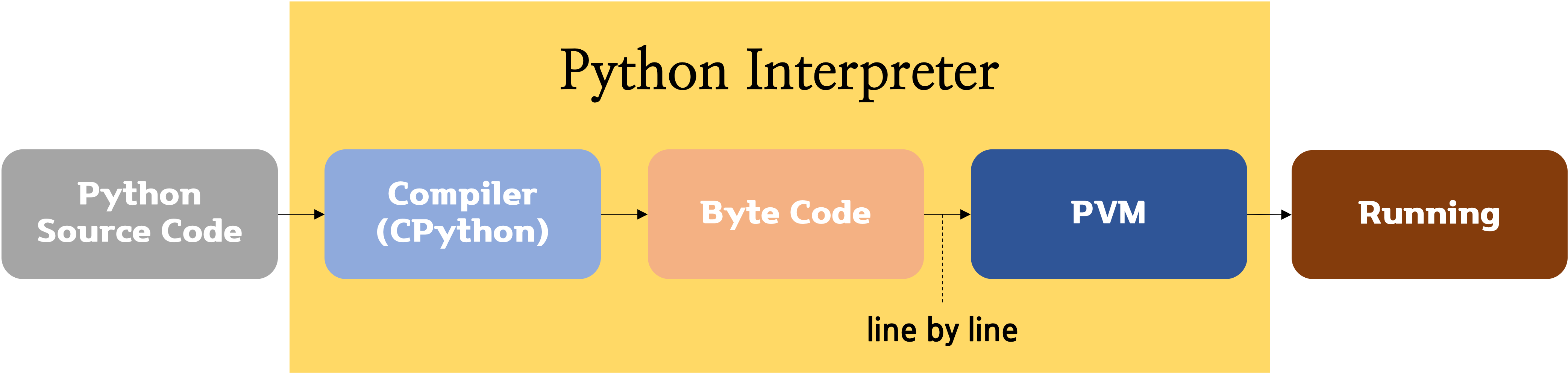
CPython은 소스 코드를 바이트 코드로 변환하는 표준 인터프리터입니다.PVM(Python Virtual Machine)은 바이트 코드를 한줄 한줄 번역하여 프로그램을 실행시킵니다.
이와 같은 특징은 위에서 살펴 보았던 하이브리드 언어의 특징과 닮아 있습니다. 혹시 파이썬 코딩을 하시면서 __pycache__ 라는 폴더를 보신적 있나요? 이 폴더에는 .pyc 라는 파일이 생성되는데요. 이 파일이 바로 CPython이 컴파일한 바이트 코드입니다.
파이썬의 작동 방식을 조금 더 자세히 나타내면 다음과 같습니다:
- Step 1: 파이썬 컴파일러가 소스 코드를 읽습니다. 그리고 나서 소스 코드가 잘 작성되었는지를 판단하기 위해 문법 오류 검사를 진행합니다. 만일 문법 오류가 발견되었다면 그 즉시 컴파일 과정을 멈추고 에러 메시지를 출력합니다.
- Step 2: 만일 에러가 발생하지 않았다면 컴파일러가 소스 코드를 바이트 코드로 변환합니다.
- Step 3: 마지막으로 바이트 코드는 PVM(Python Virtual Machine)에 보내집니다. PVM은 바이트 코드를 컴퓨터가 실행할 수 있는 기계어로 한줄 한줄 번역합니다. 만일 이 과정에서 에러가 발생하면 모든 것을 멈추고 에러 메시지를 출력합니다.
마무리
지금까지 컴파일 언어, 인터프리터 언어, 하이브리드 언어의 대한 기초 지식을 배웠습니다. 이를 통해서 파이썬은 하이브리드 언어의 성격을 가지고 있다는 것을 알 수 있었습니다. 파이썬은 단순히 코드를 한줄 한줄 기계어로 번역하지 않습니다. 먼저 컴파일러(CPython이 표준)가 파이썬 스크립트를 바이트 코드(byte code)로 변환합니다. 그리고 나서 PVM(Python Virtual Machine)이라는 일종의 소프트웨어가 바이트 코드를 한줄 한줄 기계어(machine code)로 번역하고 CPU는 이를 실행합니다. 이면에는 더 엄청난 원리가 숨어 있을 것 같지만, 제가 아직 공부가 부족하기도 하고 분량도 너무 길어지므로 본 글은 여기서 줄이도록 하겠습니다.
부록: 플랫폼 의존과 플랫폼 독립
여러 아티클에서 언어를 설명할 때 플랫폼 의존과 플랫폼 독립이라는 단어를 사용하며 설명하는데, 정확하게 와닿지 않아서 추가적으로 이에 대해 조사해보았습니다.
본질적으로 ‘언어’ 자체가 플랫폼 의존, 독립이라는 이야기는 잘못된 개념이라고 합니다. 흔히 C 언어를 플랫폼 의존적인 언어라고 많이 표현합니다. 그러나 C 언어로 코드를 짤 때, OS(윈도우, 맥, 리눅스 등)에 따라 소스 코드 자체를 다르게 짜지는 않습니다.
다만 프로그래밍 언어는 필연적으로 컴파일이라는 과정을 거쳐야 하는데, 이 컴파일이라는 과정이 OS kernel과 깊은 관련이 있다보니, OS에 따라 다른 컴파일러를 써야하는 경우가 생깁니다. 또한 컴파일러에 따라서 executable 파일의 형태가 달라지기도 합니다. 예를 들어서 윈도우에서 C 언어로 코드를 짜면 최종 결과물은 .exe 파일인데 반해, 리눅스에서의 최종 결과물은 .out 파일입니다.
.exe 파일은 리눅스에서 실행할 수 없고, .out 파일은 윈도우에서 실행할 수 없습니다. 이러한 이유로 C 언어는 플랫폼 의존적이라는 말을 많이 하는 것 같습니다. 하지만 정확히는 C 언어의 컴파일러가 플랫폼 의존적이라고 표현하는 것이 맞겠습니다.
한편 플랫폼 독립적인 언어로는 자바가 많이 언급됩니다. 자바는 파이썬과 비슷하게 바이트 코드와 가상 머신으로 이루어진 하이브리드 언어입니다. 자바로 코드를 짤 때도 역시나 OS에 따라 코드를 다르게 짜지는 않습니다. 그러나 자바의 바이트 코드인 .class 파일은 JVM이 설치된 컴퓨터면 윈도우, 맥, 리눅스 어디서나 번역 및 실행이 가능합니다. 이런면에서 자바는 플랫폼 독립적이라는 표현을 사용하는 것 같습니다.
Reference
- Why Python is Slow: Looking Under the Hood
- 프로그래밍 언어와 빌드 과정 [Build Process]
- 바이트코드와 바이너리 코드의 차이는 무엇일까?
- 바이트 코드(ByteCode) 개념.
- How Python runs?
- How Python works?
- Peephole: CPython은 어떻게 코드를 최적화하는가
- How does Python work?
- JIT 컴파일
- Python programming for the absolute beginner
- Which language platform dependent and which language platform independent?
- Is C platform dependent?
- Why is the C language platform-dependent, and why is Java platform-independent?