
 한글 인코딩 때문에 고생한 경험, 다들 있으시죠?
한글 인코딩 때문에 고생한 경험, 다들 있으시죠?
소위 말하는 인코딩이 깨진 경험을 하신적이 있지 않으신가요? 특히 맥을 처음 다루어 보신 분들께서 한글 인코딩이 깨진 경험을 많이 하셨을 것 같습니다. 분명히 윈도우에서 제대로 보이는 csv 파일이, 맥에서 열면 깨져버리죠. 이는 윈도우와 맥의 기본적인 한글 인코딩 방식이 달라서 발생하는 문제입니다. 쉽게 말해서 두 운영체제가 문자를 이해하는 시스템이 다르다는 이야기입니다.
문자 인코딩은 깊게 파보면 정말 어려운 주제 중에 하나인데요. 본 글에서는 여러가지 문자 인코딩 방식 중에서 가장 대표적인 ASCII, Unicode에 대해서 살펴보고 파이썬의 한글 인코딩 방식을 통해 실용적인 관점에서 인코딩 내용을 정리 해보려고합니다. 더욱 이론적이고 자세한 내용의 글들은 얼마든지 많으니 자세한 설명을 원하시는 분들께서는 레퍼런스를 참고해주세요.
본격적으로 글을 시작 하기 앞서, 문자 인코딩은 무엇이며 왜 필요한지에 대한 글은 여기를 참조해주세요.
ASCII(American Standard Code for Information Interchange)
ASCII는 문자를 7bit로 표현하는 표준문자체계입니다. 따라서 ASCII는 \(2^7=128\)개의 문자만 표현할 수 있는데, 이는 영문 키보드에서 사용할 수 있는 모든 문자를 표현할 수 있는 수준에 그칩니다. 그러나 표현해야하는 문자가 점차 증가함에 따라 7bit로 문자를 표현하는 것에 한계가 드러났습니다. 이후에 8bit(1byte)를 쓰는 확장 ASCII(Extended ASCII)가 등장했습니다. 확장 ASCII는 기존 ASCII에 비해 2배 많은 문자를 표현할 수 있습니다. 이를 통해 기존 ASCII로 정의하지 못했던 프랑스어, 독일어 등의 유럽어를 표현할 수 있게 되었습니다.
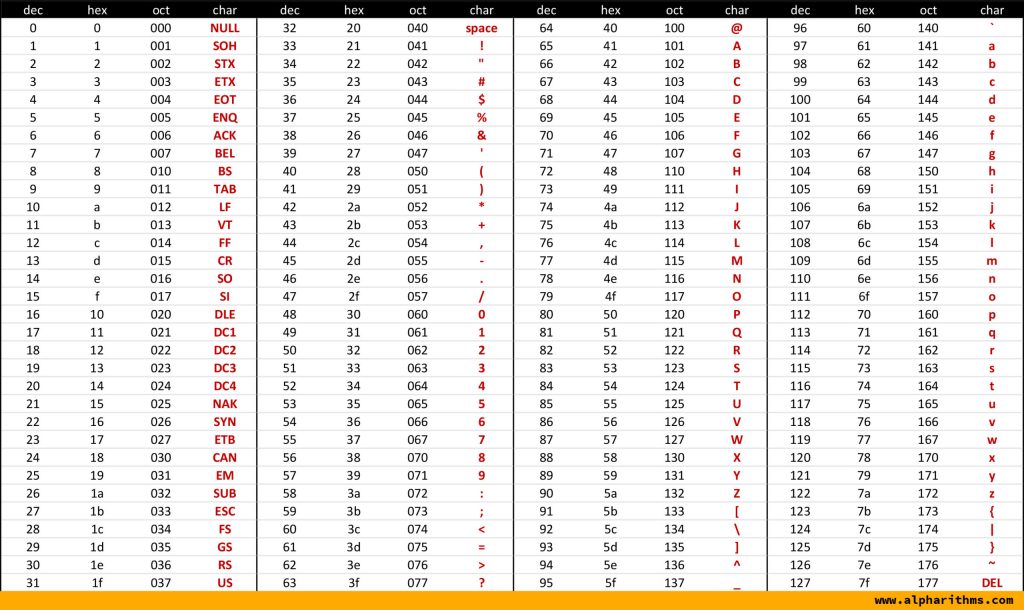 ASCII Code Table, ASCII Table: Printable Reference & Guide
ASCII Code Table, ASCII Table: Printable Reference & Guide
위의 ASCII 코드 표를 참조해서 ‘A’가 인코딩된 값을 찾아볼까요? 대문자 A는 16진수(hex)로 표현하면 41로 인코딩할 수 있네요. 이처럼 문자 인코딩은 특별한 알고리즘을 쓰는 것이 아니라 생각 보다 단순하게(?) 룰 기반인 것을 알 수 있습니다.
그러나 확장 ASCII로도 표현하지 못하는 문자들은 (당연하게도) 여전히 존재합니다. ASCII 코드 표를 보면 영어 알파벳 외의 문자는 찾아 볼 수 없죠. 그렇다면 한국어, 중국어, 일본어 등의 문자를 표현하려면 어떻게 해야할까요? 전 세계의 문자를 모두 표현할 수 있는 표준화 된 체계가 필요한 시점입니다.
Unicode
ASCII 섹션에서 살펴 보았듯이 ASCII는 전 세계의 다양한 문자를 담지 못합니다. 물론 이전부터 각 언어마다 해당 언어를 표현할 수 있는 독자적인 문자 집합(character set)은 있어 왔습니다 (EUC-KR 등). 그러나 문제는 이 독자적인 문자 집합을 어떻게 통합해서 관리하느냐 였습니다. 이 문제를 해결 하기 위해 다양한 문자 집합을 담을 표준으로 유니코드(Unicode)가 등장하게 되었습니다.
유니코드는 전 세계의 모든 문자를 일관되게 표현할 수 있는 표준문자체계입니다. 유니코드는 문자를 2~4btye의 16진수 숫자로 1:1 맵핑을 해 놓은 문자 집합(character set)입니다. 유니코드의 값을 코드 포인트(code point)라고 하는데 유니코드 문자는 보통 접두어 U+나 \u로 시작합니다. 예를 들어 A의 유니코드 코드 포인트는 U+0041로 표현됩니다(전체 표는 여기를 참조해주세요).
| U+ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | … |
|---|---|---|---|---|---|---|---|---|---|
| 0000 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | … |
| 0010 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | … |
| 0020 | ! | ” | # | $ | % | & | ’ | … | |
| 0030 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | … |
| 0040 | @ | A | B | C | D | E | F | G | … |
| 0050 | P | Q | R | S | T | U | V | W | … |
| 0060 | ` | a | b | c | d | e | f | g | … |
| 0070 | p | q | r | s | t | u | v | w | … |
여기서 하나 중요하게 짚고 넘어가야하는 포인트가 있습니다. 유니코드는 특정 인코딩 방식을 가르키는 것이 아닙니다. 다양한 문자를 16진수로 표현된 특정 숫자로 맵핑하는 표에 지나지 않습니다. 아주 다양한 문자 각각을 숫자에 1:1 대응 시켜 놓은 표인 것이죠. 그런데 컴퓨터는 무조건 0과 1로 이루어진 binary format만 이해할 수 있습니다. 예를 들어 여러분이 메모장에 ‘A’이라는 글자를 적고 이를 저장한다면 하드디스크에는 ‘A’가 0과 1로 이루어진 2진수로 변환되어 저장된다는 이야기 입니다.
A의 코드 포인트 U+0041을 2진수로 변환해봅시다. 1000001 이군요. 이걸 그대로 인코딩된 값으로 활용하면 되겠네요!
| 문자 | code point | binary |
|---|---|---|
| A | U+0041 | 1000001 |
그런데 정말 이렇게 단순하게 16진수를 2진수로 변환해서 저장하면 될까요? 다음의 예시를 보시죠. 이번엔 메모장에 ÀÈ라는 글자를 적고 텍스트 파일로 저장해 봅시다.
| 문자 | code point | binary |
|---|---|---|
| À | U+00C0 | 11000000 |
| È | U+00C8 | 11001000 |
그렇다면 하드디스크에는 1100000011001000과 같이 2진수 형태로 저장될겁니다. 자 이제 그 텍스트 파일을 실행해 봅시다. 그렇다면 컴퓨터는 2진수 데이터를 인간이 읽을 수 있는 문자로 디코딩하는데, 코드 포인트 C0C8 복원합니다. 자, 여기서 문제가 발생합니다. C0C8은 한 글자일까요 두 글자일까요? 당연히 두 글자입니다. 방금 예시를 두 글자로 들었기 때문이죠. 그런데 컴퓨터는 C0C8를 두 글자로 표현해야 한다는 것을 알 수 있을까요? 참고로 코드 포인트 C0C8은 ‘새’에 대응 됩니다.
| U+ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| C0C0 | 샀 | 상 | 샂 | 샃 | 샄 | 샅 | 샆 | 샇 | 새 |
| C0D0 | 샐 | 샑 | 샒 | 샓 | 샔 | 샕 | 샖 | 샗 | 샘 |
유니코드 코드 포인트를 단순히 2진수로 변환해서 활용하면 될 것 같았는데… 생각보다 크리티컬한 문제에 봉착하게 됩니다. 이 시점에 유니코드를 인코딩하는 시스템이 필요하게 됩니다. 유니코드 기반의 인코딩 방식으로 UTF-8, UTF-16 등이 존재합니다. 그 가운데 사실상의 표준으로 자리 잡은 UTF-8을 살펴보겠습니다.
UTF-8
UTF-8의 UTF는 ‘Unicode Transformation Format’의 약자입니다. 이름만 봐도 Unicode에 기반한 인코딩 방식임을 알 수 있습니다. 8은 문자 하나를 8bit(1byte)로 처리한다는 뜻입니다. UTF-8은 가변 길이 문자 인코딩 방식으로서 코드 포인트의 범위에 따라 문자를 1~4byte로 가변적으로 처리합니다. UTF-8은 다음과 같은 장점이 있습니다.
- 자주 사용되는 문자는 적은 비트를 할당하고 자주 사용되지 않는 문자에는 많은 비트를 할당하여 효율적으로 인코딩
- 모든 알파벳은 1byte
- 한글은 무조건 3byte
- ASCII는 UTF-8의 부분 집합임
- 즉 ASCII의 인코딩 값과 UTF-8의 인코딩 값은 정확하게 일치함
- 따라서 하위 호환성이 보장됨
UTF-16과 간단히 비교하자면, UTF-16은 문자를 2~4byte로 할당합니다. UTF-8은 1~4byte로 할당하므로 한중일 언어를 제외한 대부분의 문자는 UTF-8 방식이 더 작은 크기로 표현할 수 있습니다. 자세한 장단점에 대한 비교는 여기를 참조해주세요.
이제 UTF-8이 문자를 실제로 어떻게 인코딩 하는지 살펴봅시다. UTF-8은 아래의 테이블에 서술된 규칙에 따라 유니코드 문자를 인코딩을 합니다. 먼저 유니코드 코드 포인트를 2진수로 변환 합니다. 그리고 해당 문자의 코드 포인트의 범위를 찾아서 그 범위에 해당하는 UTF-8의 인코딩 규칙을 적용합니다. 마지막으로 xxx로 되어 있는 부분을 뒤에서부터 2진수로 채우며, 모자라는 부분은 0으로 채웁니다.
| 코드 포인트 범위(hex) | UTF-8 |
|---|---|
| 000000-00007F | 0xxxxxxx |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110zzz 10zzxxxx 10xxxxxx 10xxxxxx |
À와 È는 모두 코드 포인트의 범위가 000080-0007FF에 속합니다. 그리고 이를 2진수로 변환하면 각각 11000000, 11001000입니다. 이를 UTF-8로 인코딩 하면 각각 11000011 10000000과 11000011 10001000으로 변환됩니다. 이를 나중에 디코딩할 때는 UTF-8의 인코딩 규칙을 알고 있으므로 binary 데이터가 결국에 몇개의 문자로 이루어져있는지, 인간이 이해할 수 있는 형태의 문자는 무엇인지를 정확하게 찾아서 표현할 수 있게 되는 것입니다.
파이썬 한글 인코딩
파이썬3의 모든 문자열은 유니코드입니다.
파이썬 3.0부터는 언어의
str형은 유니코드 문자를 포함하고, 이는 어떤 문자열이든"unicode rocks!",'unicode rocks!'또는 삼중 따옴표로 묶인 문자열 문법을 사용한다면 유니코드로 저장됨을 뜻합니다.
파이썬에서 인코딩과 디코딩을 담당하는 내장함수는 각각 encode()와 decode()입니다. encode()는 유니코드 문자열을 bytes로 변환하고, decode()는 이와 반대로 bytes를 유니코드로 변환합니다. 참고로 파이썬에서 bytes는 binary 데이터를 다루는 type입니다. 계속 말씀드렸던 2진수 데이터를 파이썬에서는 bytes라는 type으로 표현한다고 보시면 되겠습니다.
인코딩
파이썬에서는 str의 encode() 메소드로 유니코드를 바이트로 변환할 수 있습니다.
str.encode()는bytes.decode()에 반대되는 메서드로서, 요청된 encoding으로 인코딩 된 유니코드 문자열의bytes를 반환하는 메서드입니다.
한글 ‘가’를 파이썬에서 utf-8로 인코딩해서 이론대로 변환이 되는지 확인 해 봅시다.
1
2
3
4
5
>>> string = '가'
>>> print(string.encode('utf-8'))
b'\xea\xb0\x80'
>>> print(type(string.encode('utf-8')))
<class bytes>
파이썬에서 ‘가’를 UTF-8로 인코딩하니 EA B0 80 이렇게 3byte의 숫자로 변환되었습니다. 일단 한글 1글자가 3byte인 것은 UTF-8의 규칙에 맞습니다. 그렇다면 우리가 배운 이론을 적용해서 실제로 EA B0 80가 나오는지 살펴보죠.
한글 ‘가’의 유니코드 코드 포인트는 U+AC00 입니다. 이를 2진수로 변환하면 1010 1100 0000 0000 입니다. 이제 위에서 배운 UTF-8 인코딩 규칙에 따라 2진수를 변환해봅시다. U+AC00은 000800-00FFFF 범위에 속하니까… 1110xxxx 10xxxxxx 10xxxxxx 이 패턴에 맞게 2진수를 뒤에서부터 채워주면 되겠네요. 그럼 11101010 10110000 10000000를 얻을 수 있습니다. 파이썬에서는 인코딩된 값을 16진수(\x)로 나타내고 있으니까 우리도 16진수로 변환해보면… EA B0 80를 얻을 수 있습니다. 직접 손으로 계산한 인코딩 값과 파이썬이 출력한 인코딩 값이 일치합니다!
| 문자 | 유니코드 코드 포인트 | 2진수 | UTF-8(Bin) | UTF-8(Hex) |
|---|---|---|---|---|
| 가 | U+AC00 | 1010 1100 0000 0000 | 11101010 10110000 10000000 | EA B0 80 |
디코딩
파이썬에서 bytes의 decode() 메서드를 통해서 bytes 문자열을 유니코드 문자열로 되돌릴 수 있습니다.
bytes.decode()는 주어진 바이트열로부터 디코딩된 문자열을 돌려줍니다. 기본 인코딩은'utf-8'입니다.
위에서 얻어낸 한글 ‘가’의 UTF-8 인코딩 값인 b'\xea\xb0\x80'를 다시 유니코드 문자열로 되돌려 보겠습니다.
1
2
3
4
5
>>> bytes_string = b'\xea\xb0\x80'
>>> print(bytes_string.decode("utf-8"))
'가'
>>> print(type(bytes_string.decode("utf-8")))
<class str>
처음에 ‘가’를 UTF-8로 인코딩한 bytes를 알아내었고, 그 bytes를 같은 인코딩 방식인 UTF-8로 디코딩 했으니 어쩌면 당연한 결과입니다. 그렇다면 인코딩과 디코딩 방식이 다르면 어떨까요?
인코딩과 디코딩 방식이 다를 때
이번에는 인코딩과 디코딩 방식이 다를 때 어떤 일이 일어나는지 살펴보겠습니다. 먼저 한글 ‘가’를 euc-kr 이라는 인코딩 방식으로 인코딩 해줍니다.
1
2
3
>>> string = '가'
>>> print(string.encode('euc-kr'))
b'\xb0\xa1'
16진수 B0 A1이라는 인코딩된 값을 얻었습니다. 이 값을 euc-kr이 아니라 UTF-8로 디코딩 해보겠습니다.
1
2
3
4
5
6
7
8
>>> print(b'\xb0\xa1'.decode('utf-8'))
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-23-d8ceaefe020b> in <module>
----> 1 print(b'\xb0\xa1'.decode('utf-8'))
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb0 in position 0: invalid start byte
UnicodeDecodeError가 발생합니다. 이는 문자가 인코딩된 방식과 디코딩된 방식의 차이에서 기인합니다. 각 인코딩 방식마다 숫자의 범위나 체계가 다르기 때문에 발생하는 일이겠죠.
마무리
지금까지 ASCII, 유니코드, UTF-8 기반의 문자 인코딩 방식에 대해서 살펴보았습니다. 컴퓨터는 0과 1로만 이루어진 2진법의 언어만 이해할 수 있습니다. 따라서 문자도 숫자로 변환해야만 우리는 서로 다른 컴퓨터 간에 문자 데이터를 주고 받을 수 있습니다. 문자를 특정 숫자로 변환하는 행위를 문자 인코딩(encoding)이라고 하고 그 반대의 행위를 문자 디코딩(decoding)이라고 합니다.
문자를 인코딩 방식은 매우 다양한데요. 각 방식마다 다룰 수 있는 문자의 개수도 다르고 변환되는 숫자도 다릅니다. 그리고 우리는 여러가지 문자 인코딩 방식에서 가장 대표적인 방식인 ASCII, Unicode, UTF-8에 대해서 살펴보았습니다. 각각의 아주 세부적인 내용까지는 정리하진 않았지만, 코딩을 하면서 만날 수 있는 여러가지 문자 인코딩 에러를 이해하고 대처할 수 있는 기초 체력을 기르다는 관점으로 접근해 보았습니다.